(800) 696-4690
Let’s Talk Contact Us


Need Help With Your Marketing?

Another Google Step Against Scraped Content?

Just last week, Google announced a new tool for reporting scraped content URLs that rank above the original content URLs. The search engine’s own Matt Cutts tweeted, “If you see a scraper URL outranking the original source of content in Google, please tell us about it:” with a link to the new scraper report.
About the Google Scraper Report
The scraper report asks you to report the following: the URL of the original content the URL with the scraped content the URL of the Google search result where the scraped content is outranking the original content. And finally, Google asks you to confirm that your site doesn’t currently have a manual action against it.
What Is Scraped Content
At a glance, it appears that the scraper report could be Google’s attempt to take scraped content more seriously and prevent it from ranking. In case you’re unaware, content is considered scraped whenever it’s
- copied from another website completely
- copied without adding an original content or extra value
- copied and only loosely modified
- etc.
What Happens After You Use the Scraper Report?
Google doesn’t make that clear.
Will the other site get penalized? Maybe. Just this past January, Google announced a penalty warning against thin and scraped content. Chris Nelson on the Google search quality team said that affiliates that produce thin content or use scraped content and little to no value on their website may get a penalty for defying Google’s quality guidelines.
Nonetheless, Google has not directly said what will happen once a scraper URL is submitted.
The Problem with Scraper URLs
In January, BuzzFeed (I’m as surprised as you are) ran an article called “Why Does Google Still Reward Content Scraping?”. To summarize the article:
- The Verge wrote a piece on “For Amusement Only: The life and death of the American arcade.”
- The Huffington Post copied the intro from the article, linked to the article, and slapped an almost identical headline on it: “The Life and Death of the American Arcade.”
- The Huffington Post article ended up outranking the original article.
- The Verge asked the The Huffington Post to take the article down.
Many commenters on the article actually feel that The Huffington Post did The Verge a favor. You can imagine how much referral traffic a site could get with a link from The Huffington Post. Maybe more traffic than the site would have gotten from being first in organic search results. It’s hard to say.
One thing is clear: according to Google’s definition of scraped content, this is definitely a solid example of content scraping.
Now if The Verge chose to use Google’s scraped content tool, would The Huffington Post get a penalty? It’s hard to believe, but I suppose it wouldn’t be the first time that Google’s punished a big brand.
Google Breaks Its Own Guidelines?
Shortly after Matt Cutts tweeted about the scraper report, SEO nerds everywhere had a laugh at the following Dan Barker tweet:
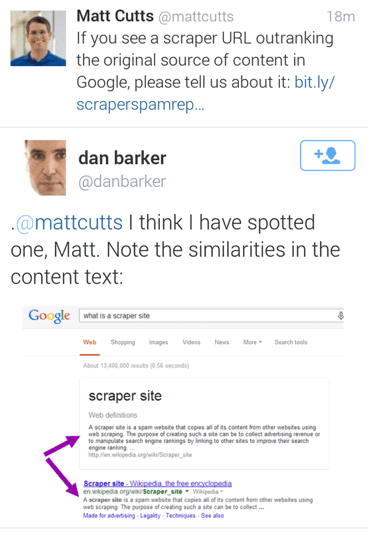
The tweet ended up going viral and begged the question of whether Google’s scraped content penalty is at least a bit hypocritical. Danny Sullivan covered the topic nicely over at Search Engine Land.
Either way, it’s clear that in order to rank in Google’s results, unique content content seems to be the way to go. We’ve been saying this at Blue Corona for awhile now, but the new scraper tool only reinforces the idea.

About The Author: Blue Corona's Editorial Staff is determined to help you increase your leads and sales, optimize your marketing costs, and differentiate your brand by passing on our tribal knowledge. The team vigilantly stays on top of the latest in digital marketing, bringing you the top insights with expert commentary. Want to see something on our blog you haven't seen yet? Shoot us an email and our marketing team will get to work.
View more blogs by Blue Corona
Maryland
7595 Rickenbacker Drive
Gaithersburg, MD 20879
Gaithersburg, MD 20879