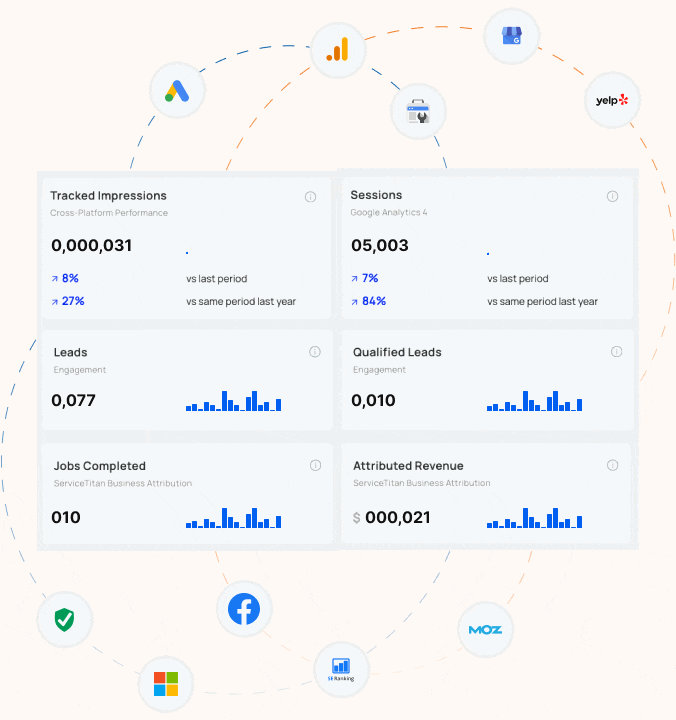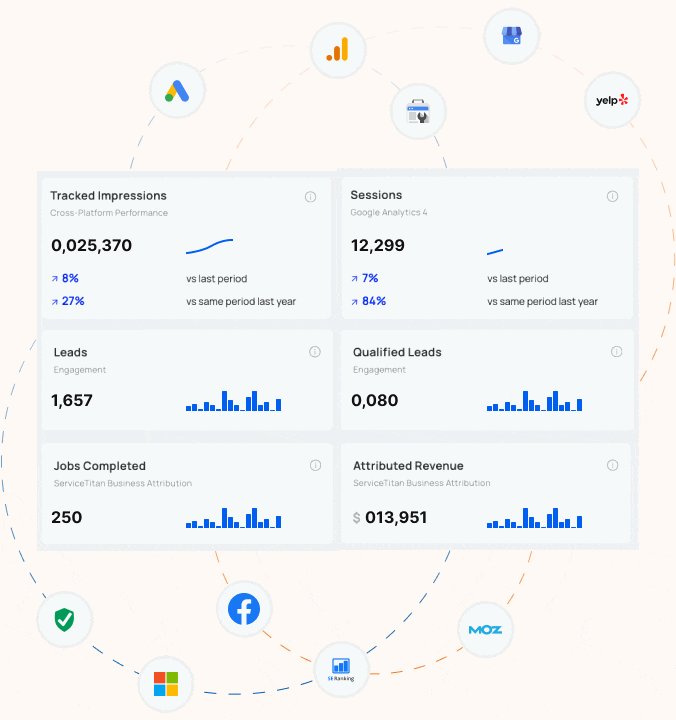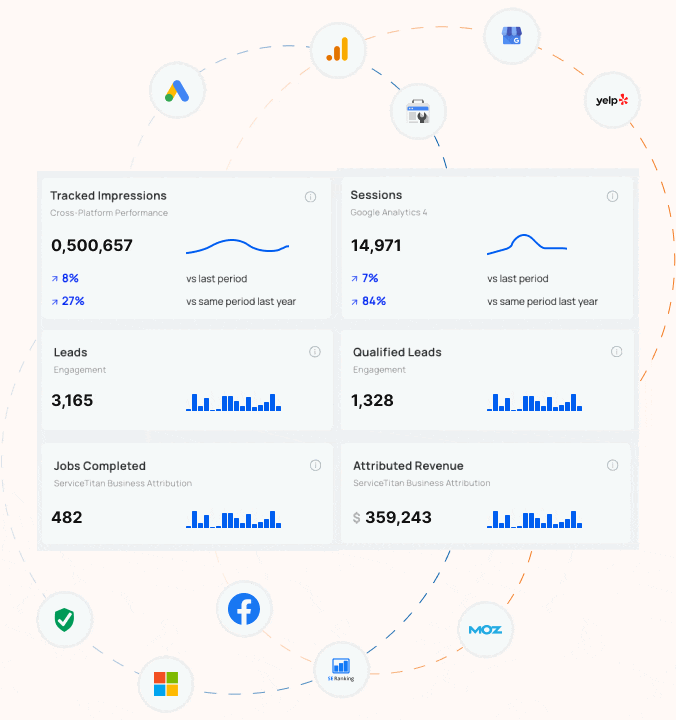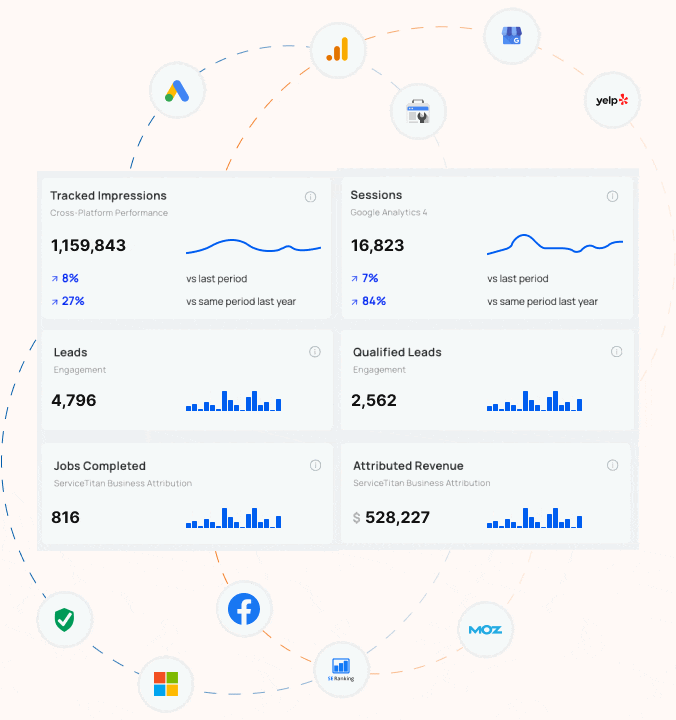
What Every Contractor Needs to Know about Google’s Third-Party Cookie Deprecation
Google first announced its decision to phase out third-party cookies in Chrome in 2020, however, the depreciation was delayed several times. Now, Google has pushed...
Read More
6 minutes